
When working with memory constrained devices you may not able to keep all the training data in memory: passive-aggressive classifiers may help solve your memory problems.
Batch learning
A couple weeks ago I started exploring the possibility to train a machine learning classifier directly on a microcontroller. Since I like SVM, I ported the simplified SVM SMO (Sequential Minimal Optimization) algorithm to plain C, ready to be deployed to embedded devices.
Now, that kind of algorithm works in the so-called "batch-mode": it needs all the training data to be available in memory to learn.
This may be a limiting factor on resource-constrained devices, since it poses an upper bound to the number of samples you can train on. And when working with high-dimensional datasets, the number of samples could be not enough to achieve good accuracy.
Enter incremental learning
To solve this limitation, you need a totally different kind of learning algorithms: you need incremental (a.k.a online a.k.a out of core) learning.
Incremental learning works by inspecting one training sample at a time, instead of all at once.
The clear advantage is that you have a tiny memory footprint. And this is a huge advantage.
The clear disadvantage is that you don't have the "big picture" of your data, so:
- the end result will probably be affected by the order of presentation of the samples
- you may not be able to achieve top accuracy
Passive-aggressive classifier
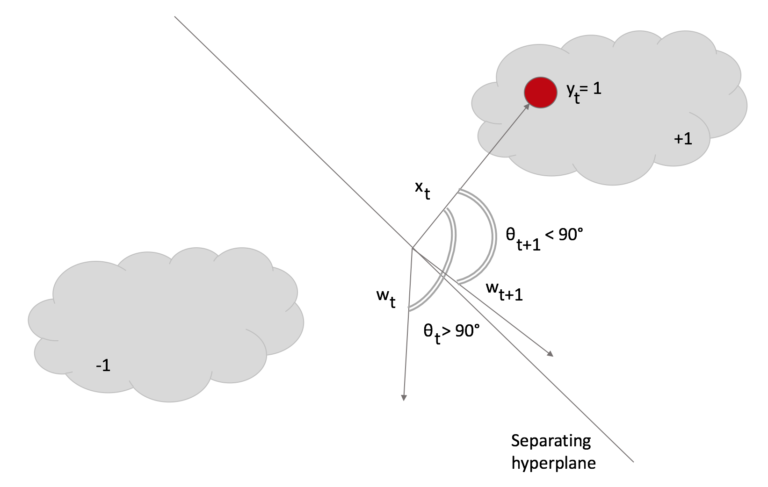
Passive-aggressive classification is one of the available incremental learning algorithms and it is very simple to implement, since it has a closed-form update rule.
Please refer to this short explanation on Passive-aggressive classifiers for a nice description with images.
The core concept is that the classifier adjusts it weight vector for each mis-classified training sample it receives, trying to get it correct.
Benchmarks
I run a couple benchmark on my Esp32 to assess both accuracy and training time.
First of all: it is fast!. When I say it is fast I mean it takes ~1ms to train on 400 samples x 30 features each.
Talking about accuracy instead... Uhm...
Accuracy vary. Greatly.
You can achieve 100% on some datasets.
And 40% on others. But on those same datasets you can achieve >85% if training on a different number of samples. Or in a different order.
I guess this is the tradeoff for such a simple and space-efficient algorithm.
I report my results in the following table. It is not meant to be an exhaustive benchmark of the classifier, since those number will vary based on the order of presentation, but still you can get an idea of what it is able to achieve.
| Dataset size | Train samples | Accuracy |
|---|---|---|
| BREAST CANCER | ||
| 567 samples | 20 | 62 |
| 30 features | 40 | 37 |
| 60 | 63 | |
| 100 | 39 | |
| 150 | 38 | |
| 200 | 64 | |
| 250 | 61 | |
| 300 | 69 | |
| 350 | 73 | |
| 400 | 85 | |
| IRIS | ||
| 100 samples | 10 | 50 |
| 4 features | 20 | 51 |
| 40 | 100 | |
| 60 | 100 | |
| 80 | 100 | |
| DIGITS | ||
| 358 samples | 20 | 98 |
| 64 features | 40 | 98 |
| 60 | 99 | |
| 100 | 100 | |
| 150 | 100 | |
| 200 | 99 | |
| 250 | 98 | |
| 300 | 95 | |
| CLEVELAND HEART DISEASE | ||
| 212 samples | 20 | 76 |
| 13 features | 40 | 24 |
| 60 | 77 | |
| 100 | 19 | |
| 120 | 82 | |
| 140 | 78 | |
| 180 | 88 |
Time to code
Here I'll report an extract of the example code you can find on Github for this classifier.
#include "EloquentPassiveAggressiveClassifier.h"
#include "EloquentAccuracyScorer.h"
#include "iris.h"
using namespace Eloquent::ML;
void loop() {
int trainSamples;
PassiveAggressiveClassifier<FEATURES_DIM> clf;
AccuracyScorer scorer;
trainSamples = readSerialNumber("How many samples will you use as training?", DATASET_SIZE - 2);
if (trainSamples == 0)
return;
clf.setC(1);
// train
for (uint16_t i = 0; i < trainSamples; i++)
clf.fitOne(X[i], y[i]);
// predict
for (uint16_t i = trainSamples; i < DATASET_SIZE; i++) {
int predicted = clf.predict(X[i]);
int actual = y[i] > 0 ? 1 : -1;
scorer.scoreOne(actual, predicted);
}
Serial.print("Accuracy: ");
Serial.print(round(100 * scorer.accuracy()));
Serial.print("% out of ");
Serial.print(scorer.support());
Serial.println(" predictions");
}On the project page you will find the code to reproduce these numbers.