
Stochastic gradient descent is a well know algorithm to train classifiers in an incremental fashion: that is, as training samples become available. This saves you critical memory on tiny devices while still achieving top performance! Now you can use it on your microcontroller with ease.
A brief recap on Stochastic Gradient Descent
If you ever worked with Machine learning, you surely know about Gradient descent: it is an iterative algorithm to optimize a loss function.
It is much general-purpose, in the sense that it is not bound to a particular application, but it has been heavily used in Neural networks in the recent years.
Yet, it can be used as a classifier on its own if you set its loss function as the classification error.

This is the core update rule of Gradient descent: quite simple.
As you see, there's a summation in the formula: this means we need to cycle through the entire training set to compute the update to the weights.
In case of large datasets, this can be slow or not possible at all.
And requires a lot of memory.
And we don't have memory on microcontrollers.
So we need Stochastic gradient descent.
Stochastic gradient descent has the same exact update rule, but it is applied on the single training sample.
Imagine the summation goes from 1 to 1, instead of m.
That's it.
How to use
The pattern of use is similar to that of the Passive Aggressive classifier: you have the fitOne and predict methods.
First of all, download the library from Github.
#include <EloquentSGD.h>
#include <EloquentAccuracyScorer.h>
#include "iris.h"
#define VERBOSE
using namespace Eloquent::ML;
void setup() {
Serial.begin(115200);
delay(3000);
}
void loop() {
int trainSamples;
int retrainingCycles;
SGD<FEATURES_DIM> clf;
AccuracyScorer scorer;
// ....
// train
for (uint16_t cycle = 0; cycle < retrainingCycles; cycle++)
for (uint16_t i = 0; i < trainSamples; i++)
clf.fitOne(X[i], y[i]);
// predict
for (uint16_t i = trainSamples; i < DATASET_SIZE; i++) {
int predicted = clf.predict(X[i]);
int actual = y[i];
scorer.scoreOne(actual, predicted);
}
Serial.print("Accuracy: ");
Serial.print(round(100 * scorer.accuracy()));
Serial.print("% out of ");
Serial.print(scorer.support());
Serial.println(" predictions");
}In this case we're working with known datasets, so we cycle through them for the training, but if you're learning "on-line", from samples generated over time, it will work exactly the same.
A bit of momentum
Stochastic gradient descent works quite well out of the box in most cases.
Sometimes, however, its updates can start "oscillating".
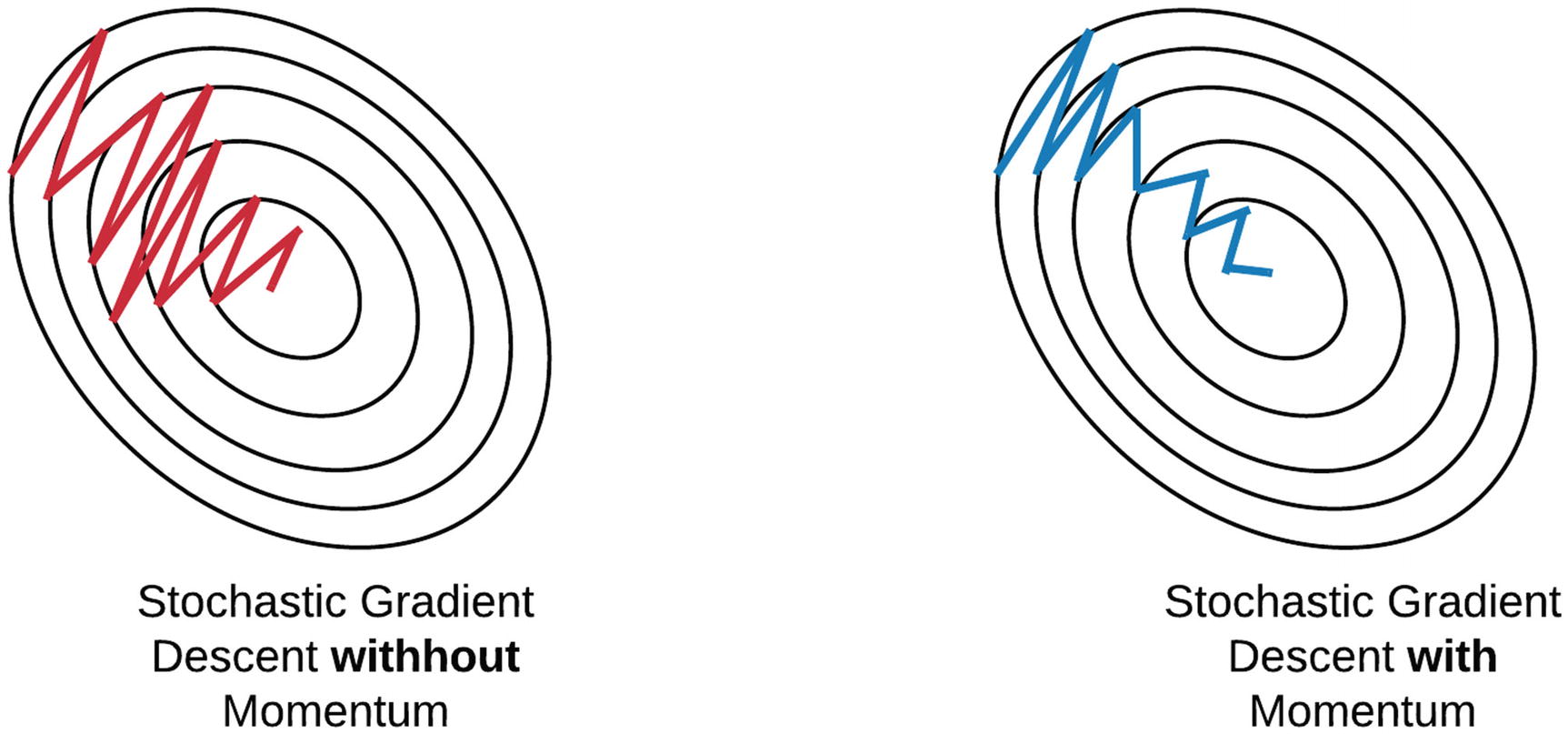
To solve this problem, it has been proposed the momentum technique, which can both speed up learning and increase the accuracy.
In my personal tests, I was able to achieve up to +5% in accuracy on the majority of datasets.
To use it, you only need to set a decay factor between 0 and 1.
SGD clf;
clf.momentum(0.5);Run on your own
On Github you can find the full example with some benchmark datasets to try on your own.
The example is interactive an will ask you how many samples to use for the training and how many times to cycle through them.
This is something you should consider: if you have a training set and can store it somehow (in memory or on Flash for example), re-presenting the same samples to the SGD classifier could (and probably will) increase its performance if done correctly.
This happens because the algorithm needs some time to converge and if it doesn't receive enough samples it won't learn properly.
Of course, if you re-use the same samples over and over again, you're likely to overfit.