
As of now, we know it is possible to run Machine learning inference on tiny microcontrollers thanks to Tensorflow for Micro and my very own library MicroML. What if you could train a classifier directly on the microcontroller, too?
When I first started this journey in the world of Machine learning on microcontrollers, one fact was set in stone for me: you train your classifier once and for all on a PC, then deploy it to your microcontroller.
As simple as this.
Training is a heavy process, requires lots of computations and memory. You just want a machine as powerful as possible to carry out this task as fast as possible.
Moreover, it is a one-time task: once your classifier has been trained, it needs not to be updated anymore.
And this yield true until now.
Until my reader Joao Carvalho, in the comments on the post about an alternative to SVM which produces much smaller models that I strongly invite you to read, challenged me with this idea of running the SVM training directly on the microcontroller.
In the past I replied "No way" to people asking about this topic on forums, but Joao was so kind to link me a Javascript implementation of the simplified SVM SMO (Sequential Minimal Optimization) algorithm.
At a first glance it looked quite easy to port from Javascript to C, so I gave it a try.
And in fact it only took me 30 minutes to get it working on my PC.
Then I deployed it to my ESP32 and... it worked!
My first try was with 10 samples from the the IRIS dataset: it only took almost no time to train.
But I know SVM training and inferencing time grows rapidly with the number of training samples.
Execution time will be the most limiting factor for this kind of task, so I created a benchmarking setup to evaluate the performance of the algorithm on different dataset sizes and features dimensions.
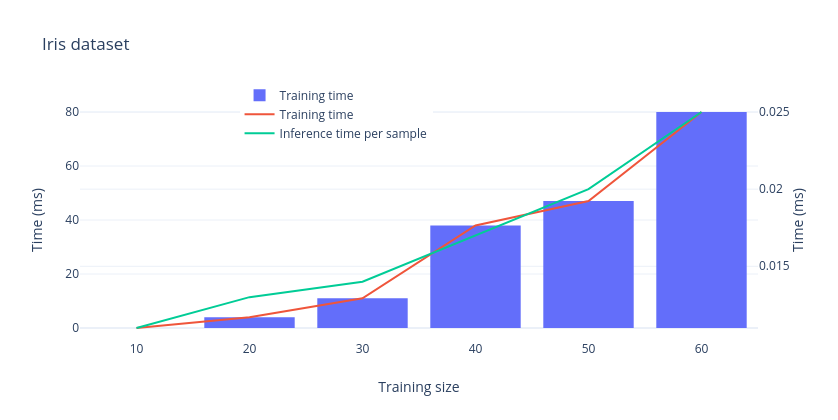
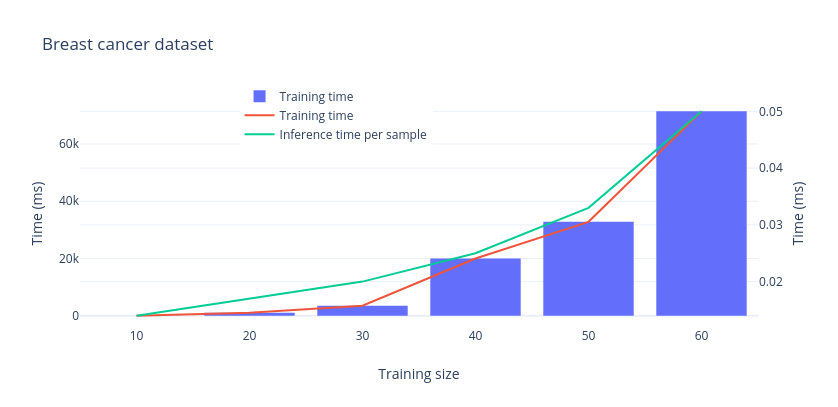
The results are summarized in the following table and plots.
| Features size | Training size | Training time (ms) | Unit inference time (ms) | Accuracy |
|---|---|---|---|---|
| 4 | 10 | 0 | 0,011 | 80 |
| 4 | 20 | 4 | 0,013 | 85 |
| 4 | 30 | 11 | 0,014 | 90 |
| 4 | 40 | 38 | 0,017 | 91 |
| 4 | 50 | 47 | 0,020 | 86 |
| 4 | 60 | 80 | 0,025 | 87 |
| 30 | 10 | 22 | 0,014 | 71 |
| 30 | 20 | 1000 | 0,017 | 61 |
| 30 | 30 | 3500 | 0,020 | 66 |
| 30 | 40 | 20000 | 0,025 | 85 |
| 30 | 50 | 32800 | 0,033 | 83 |
| 30 | 60 | 71400 | 0,050 | 80 |
* all benchmark are obtained on an ESP32 board
** the inference took actually sometimes less than 1ms to run for all the test samples, so it was rounded to 1ms and divided by the number of samples
We can see from the table that for the Iris dataset, which has 4-dimensional features, the training process is quite fast: 80ms to train on 60 samples.
Things become much different when training on the Breast cancer dataset, with its 30 features per sample. Now we're talking abouts seconds to train and even minutes when increasing the number of samples to 60.
Fortunately the inference time stays almost flat, so you will have real-time predictions.
Downsides
Of course there're downsides: it's not a perfect world.
Convergence
I actually don't know, in practice, what this means. But it sounds like a bad thing.
Binary classification only
As of now this algorithm can only do binary classification.
I hope to implement multi-class classification in the future with the one-vs-all approach, but I don't really know if it would be too inefficient for a microcontroller to run.
Declining accuracy
If you look at the benchmark table above, also, you'll notice the accuracy does not always increase linearly with the training samples size. It seems it reaches an optimum and then starts decreasing.
If you're going to deploy your device in an autonomous scenario, you'll need to monitor your accucary every time you re-train it, or your results are going to go poor.
You should keep track of the optimum you achieved and roll-back to its training set when you register a declining accuracy.
Memory
You will need to keep all your training set in memory for the classifier to both learn and predict. This means RAM will be a limiting factor and we know RAM is an expensive resource on microcontrollers.
You will have to find a good enough compromise between the number of features, the number of samples and the accuracy.
Time to get your hands on
I created a sample project for you to train a color classifier with a super simple setup: you will only need a TCS3200 (color sensor) to follow along.
Dont' have a TCS3200? No problem, you can train a classifier on the IRIS dataset
If you've read so far, please consider letting me know in the comments some useful applications you can think about this new tool. It's a brand new topic for me and I'll appreciate any of your suggestion.
Check the project repo on Github