
So far we've used SVM (Support Vector Machine) as our main classifier to port a Machine learning model to a microcontroller: but recently I found an interesting alternative which could be waaaay smaller, mantaining a similar accuracy.
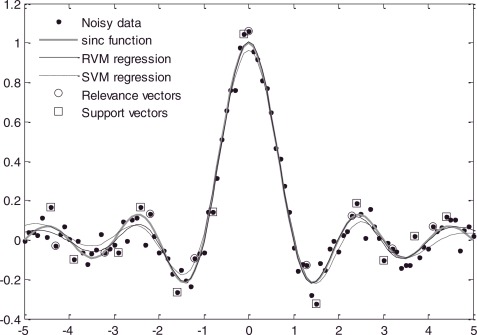
Table of contents
The current state
I chose SVM as my main focus of intereset for the MicroML framework because I knew the support vector encoding could be very memory efficient once ported to plain C. And it really is.
I was able to port many real-world models (gesture identification, wake word detection) to tiny microcontrollers like the old Arduino Nano (32 kb flash, 2 kb RAM).
The tradeoff of my implementation was to sacrifice the flash space (which is usually quite big) to save as much RAM as possible, which is usually the most limiting factor.
Due to this implementation, if your model grows in size (highly dimensional data or not well separable data), the generated code will still fit in the RAM, but "overflow" the available flash.
In a couple of my previous post I warned that model selection might be a required step before being able to deploy a model to a MCU, since you should first check if it fits. If not, you must train another model hoping to get fewer support vectors, since each of them contributes to the code size increase.
A new algorithm: Relevance Vector Machines
It was by chance that I came across a new algorithm that I never heard of, called Relevance Vector Machine. It was patented by Microsoft until last year (so maybe this is the reason you don't see it in the wild), but now it is free of use as far as I can tell.
Here is the link to the paper if you want to read it, it gives some insights into the development process.
I'm not a mathematician, so I can't describe it accurately, but in a few words it uses the same formulation of SVM (a weightened sum of kernels), applying a Bayesan model.
This serves in the first place to be able to get the probabilities of the classification results, which is something totally missing in SVM.
In the second place, the algorithm tries to learn a much more sparse representation of the support vectors, as you can see in the following picture.
When I first read the paper my first tought was just "wow"! This is exactly what I need for my MicroML framework: a ultra-lightweight model which can still achieve high accuracy.
Training a classifier
Now that I knew this algorithm, I searched for it in the sklearn documentation: it was not there.
It seems that, since it was patented, they didn't have an implementation.
Fortunately, there is an implementation which follows the sklearn paradigm. You have to install it:
pip install Cython
pip install https://github.com/AmazaspShumik/sklearn_bayes/archive/master.zipSince the interface is the usual fit predict, it is super easy to train a classifier.
from sklearn.datasets import load_iris
from skbayes.rvm_ard_models import RVC
import warnings
# I get tons of boring warnings during training, so turn it off
warnings.filterwarnings("ignore")
iris = load_iris()
X = iris.data
y = iris.target
clf = RVC(kernel='rbf', gamma=0.001)
clf.fit(X, y)
y_predict = clf.predict(X)The parameters for the constructor are similar to those of the SVC classifier from sklearn:
kernel: one of linear, poly, rbfdegree: ifkernel=polygamma: ifkernel=polyorkernel=rbf
You can read the docs from sklearn to learn more.
Porting to C
Now that we have a trained classifier, we have to port it to plain C that compiles on our microcontroller of choice.
I patched my package micromlgen to do the job for you, so you should install the latest version to get it working.
pip install --upgrade micromlgenNow the export part is almost the same as with an SVM classifier.
from micromlgen import port_rvm
clf = get_rvm_classifier()
c_code = port_rvm(clf)
print(c_code)And you're done: you have plain C code you can embed in any microcontroller.
Performace comparison
To test the effectiveness of this new algorithm, I applied it to the datasets I built in my previous posts, comparing side by side the size and accuracy of both SVM and RVM.
The results are summarized in the next table.
| Dataset | SVM | RVM | Delta | |||
|---|---|---|---|---|---|---|
| Flash(byte) | Acc. (%) | Flash(byte) | Acc. (%) | Flash | Acc. | |
| RGB colors | 4584 | 100 | 3580 | 100 | -22% | -0% |
| Accelerometer gestures(linear kernel) | 36888 | 92 | 7056 | 85 | -80% | -7% |
| Accelerometer gestures(gaussian kernel) | 45348 | 95 | 7766 | 95 | -82% | -0% |
| Wifi positioning | 4641 | 100 | 3534 | 100 | -24% | -0% |
| Wake word(linear kernel) | 18098 | 86 | 3602 | 53 | -80% | -33% |
| Wake word(gaussian kernel) | 21788 | 90 | 4826 | 62 | -78% | -28% |
** the accuracy reported are with default parameters, without any tuning, averaged in 30 runs
As you may see, the results are quite surpising:
- you can achieve up to 82% space reduction on highly dimensional dataset without any loss in accuracy (accelerometer gestures with gaussian kernel)
- sometimes you may not be able to achieve a decent accuracy (62% at most on the wake word dataset)
As in any situation, you should test which one of the two algorithms works best for your use case, but there a couple of guidelines you may follow:
- if you need top accuracy, probably SVM can achieve slighter better performance if you have enough space
- if you need tiny space or top speed, test if RVM achieves a satisfiable accuracy
- if both SVM and RVM achieve comparable performace, go with RVM: it's much lighter than SVM in most cases and will run faster
Size comparison
As a reference, here is the codes generated for an SVM classifier and an RVM one to classify the IRIS dataset.
uint8_t predict_rvm(double *x) {
double decision[3] = { 0 };
decision[0] = -0.6190847299428206;
decision[1] = (compute_kernel(x, 6.3, 3.3, 6.0, 2.5) - 72.33233 ) * 0.228214 + -2.3609625;
decision[2] = (compute_kernel(x, 7.7, 2.8, 6.7, 2.0) - 81.0089166 ) * -0.29006 + -3.360963;
uint8_t idx = 0;
double val = decision[0];
for (uint8_t i = 1; i < 3; i++) {
if (decision[i] > val) {
idx = i;
val = decision[i];
}
}
return idx;
}
int predict_svm(double *x) {
double kernels[10] = { 0 };
double decisions[3] = { 0 };
int votes[3] = { 0 };
kernels[0] = compute_kernel(x, 6.7 , 3.0 , 5.0 , 1.7 );
kernels[1] = compute_kernel(x, 6.0 , 2.7 , 5.1 , 1.6 );
kernels[2] = compute_kernel(x, 5.1 , 2.5 , 3.0 , 1.1 );
kernels[3] = compute_kernel(x, 6.0 , 3.0 , 4.8 , 1.8 );
kernels[4] = compute_kernel(x, 7.2 , 3.0 , 5.8 , 1.6 );
kernels[5] = compute_kernel(x, 4.9 , 2.5 , 4.5 , 1.7 );
kernels[6] = compute_kernel(x, 6.2 , 2.8 , 4.8 , 1.8 );
kernels[7] = compute_kernel(x, 6.0 , 2.2 , 5.0 , 1.5 );
kernels[8] = compute_kernel(x, 4.8 , 3.4 , 1.9 , 0.2 );
kernels[9] = compute_kernel(x, 5.1 , 3.3 , 1.7 , 0.5 );
decisions[0] = 20.276395502
+ kernels[0] * 100.0
+ kernels[1] * 100.0
+ kernels[3] * -79.351629954
+ kernels[4] * -49.298850195
+ kernels[6] * -40.585178082
+ kernels[7] * -30.764341769
;
decisions[1] = -0.903345464
+ kernels[2] * 0.743494115
+ kernels[9] * -0.743494115
;
decisions[2] = -1.507856504
+ kernels[5] * 0.203695177
+ kernels[8] * -0.160020702
+ kernels[9] * -0.043674475
;
votes[decisions[0] > 0 ? 0 : 1] += 1;
votes[decisions[1] > 0 ? 0 : 2] += 1;
votes[decisions[2] > 0 ? 1 : 2] += 1;
int classVal = -1;
int classIdx = -1;
for (int i = 0; i < 3; i++) {
if (votes[i] > classVal) {
classVal = votes[i];
classIdx = i;
}
}
return classIdx;
}As you can see, RVM actually only computes 2 kernels and does 2 multiplications. SVM, on the other hand, computes 10 kernels and does 13 multiplications.
This is a recurring pattern, so RVM is much much faster in the inference process.
Troubleshooting
It can happen that when running micromlgen.port(clf) you get a TemplateNotFound error. To solve the problem, first of all uninstall micromlgen.
pip uninstall micromlgenThen head to Github, download the package as zip and extract the micromlgen folder into your project.
Disclaimer
micromlgen and in particular port_rvm are work in progress: you may experience some glitches or it may not work in your specific case. Please report any issue on the Github repo.